Overview
The expert who knew everything, and froze on camera.
DeepHow's platform relies on subject-matter experts recording step-by-step training videos. The problem wasn't a lack of expertise. It was the pressure of presenting it. The floor technician who'd mastered a machine over 20 years, the quality inspector with encyclopedic process knowledge , many of them froze the moment a camera pointed at them.
Some were self-conscious about their accent. Some found narration too slow and unnatural. Others simply didn't want to be on camera. The result was an operational bottleneck: the people most qualified to teach were the least likely to record.
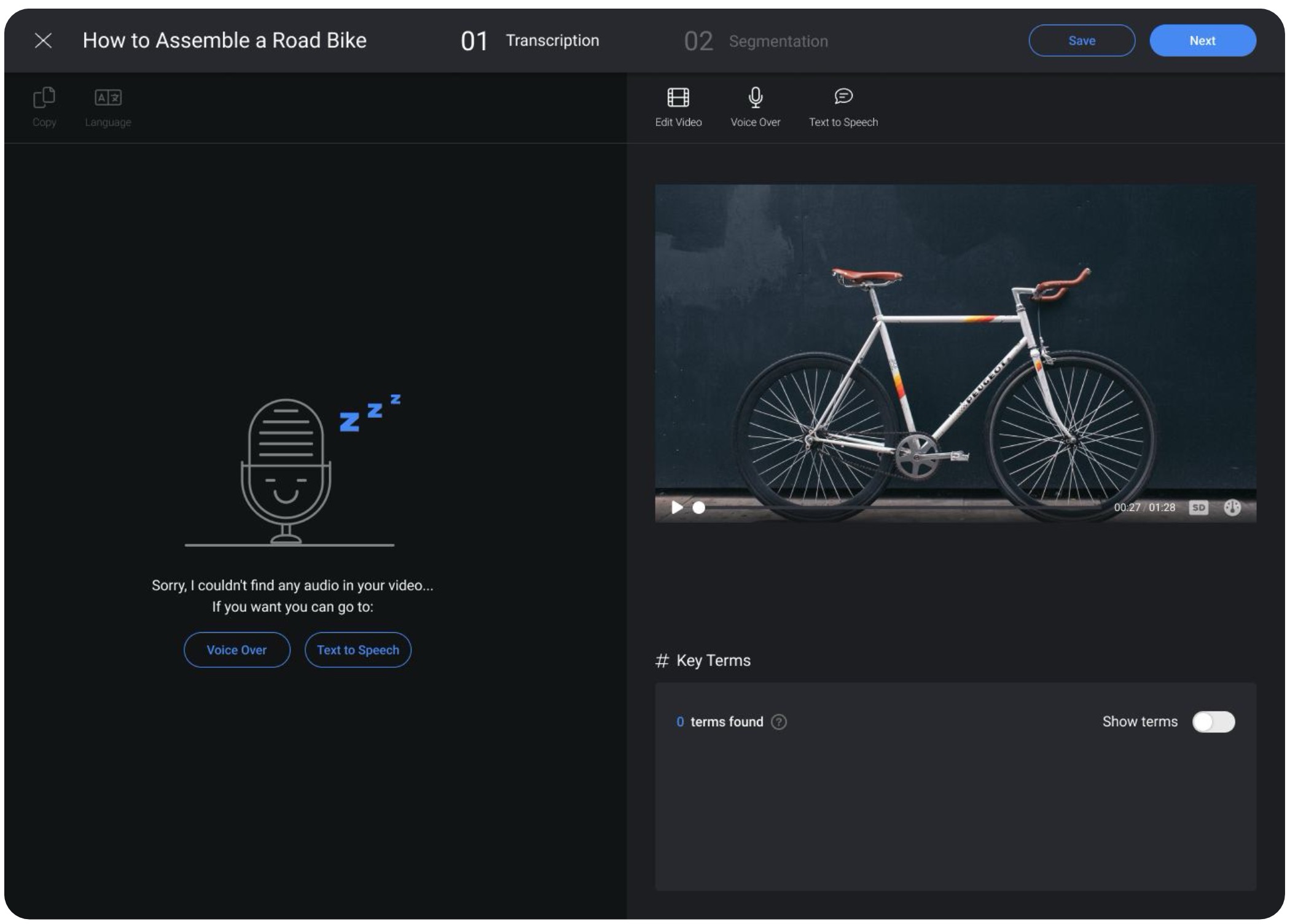
DeepHow needed a way for experts to contribute their knowledge without requiring them to become performers. Text to Speech was the answer.
Deep expertise doesn't always translate into confidence on camera. The experts who had the most to share were often the least comfortable sharing it.
My Role
Research-led, end-to-end.
- Led all design from research through post-launch iteration
- Ran user research to understand pain points around the existing recording workflow
- Designed the full UX flow for TTS creation, voice selection, and timeline sync
- Collaborated with engineering to work within existing backend constraints
- Responded to a post-launch client request that evolved the feature into a multilingual tool
- Designed the one-click translation flow, architected within existing infrastructure
Decisions
The choices that shaped the product.
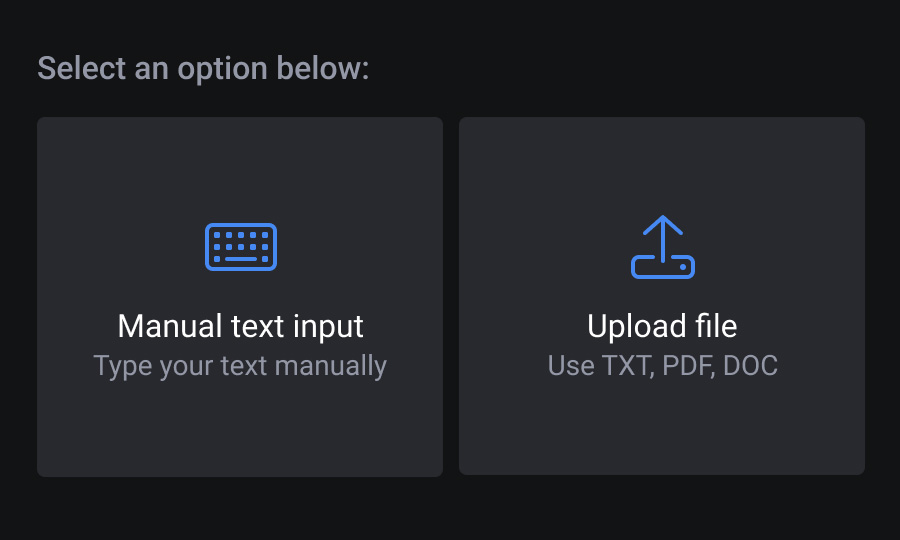
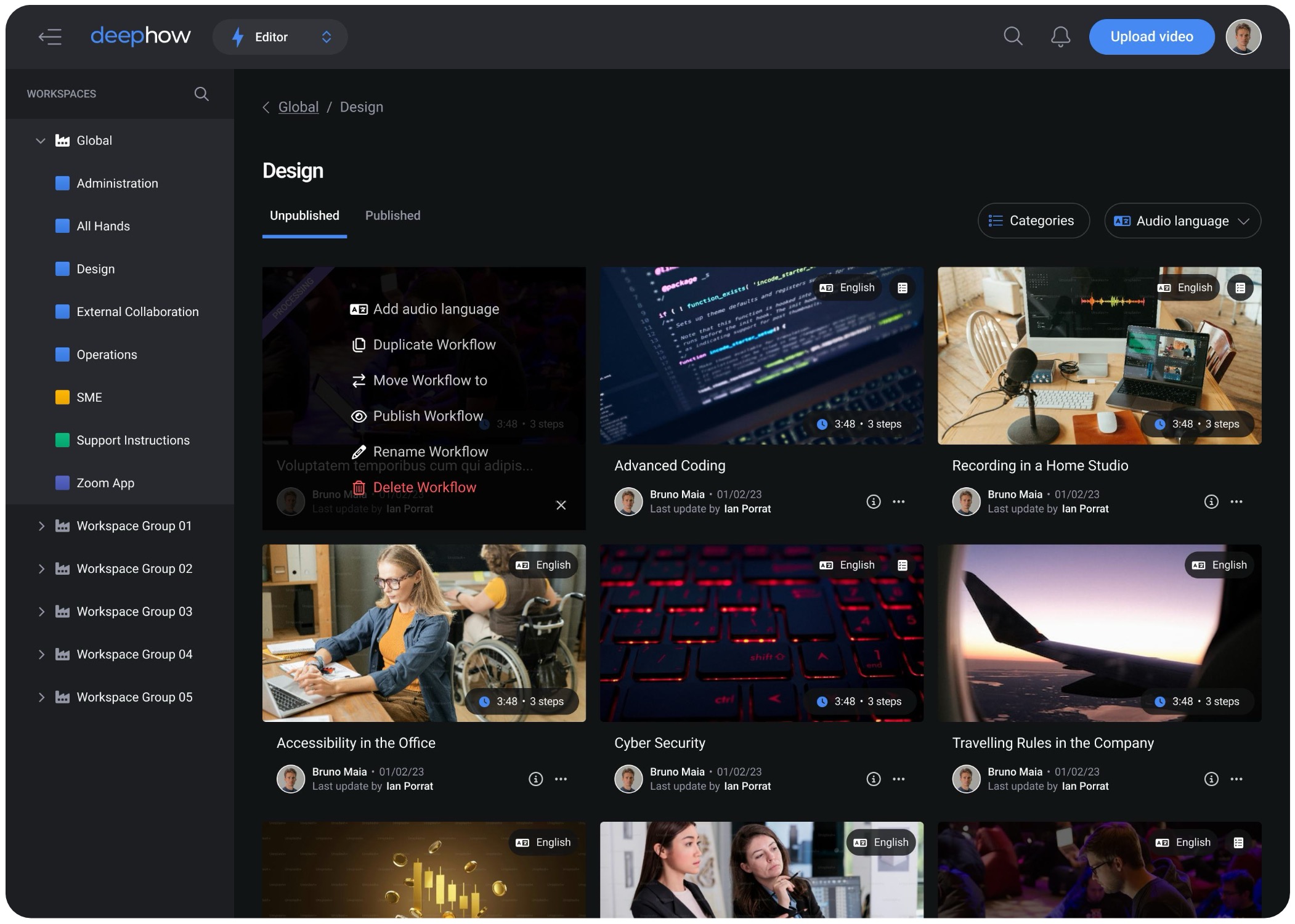
Remove content creation friction
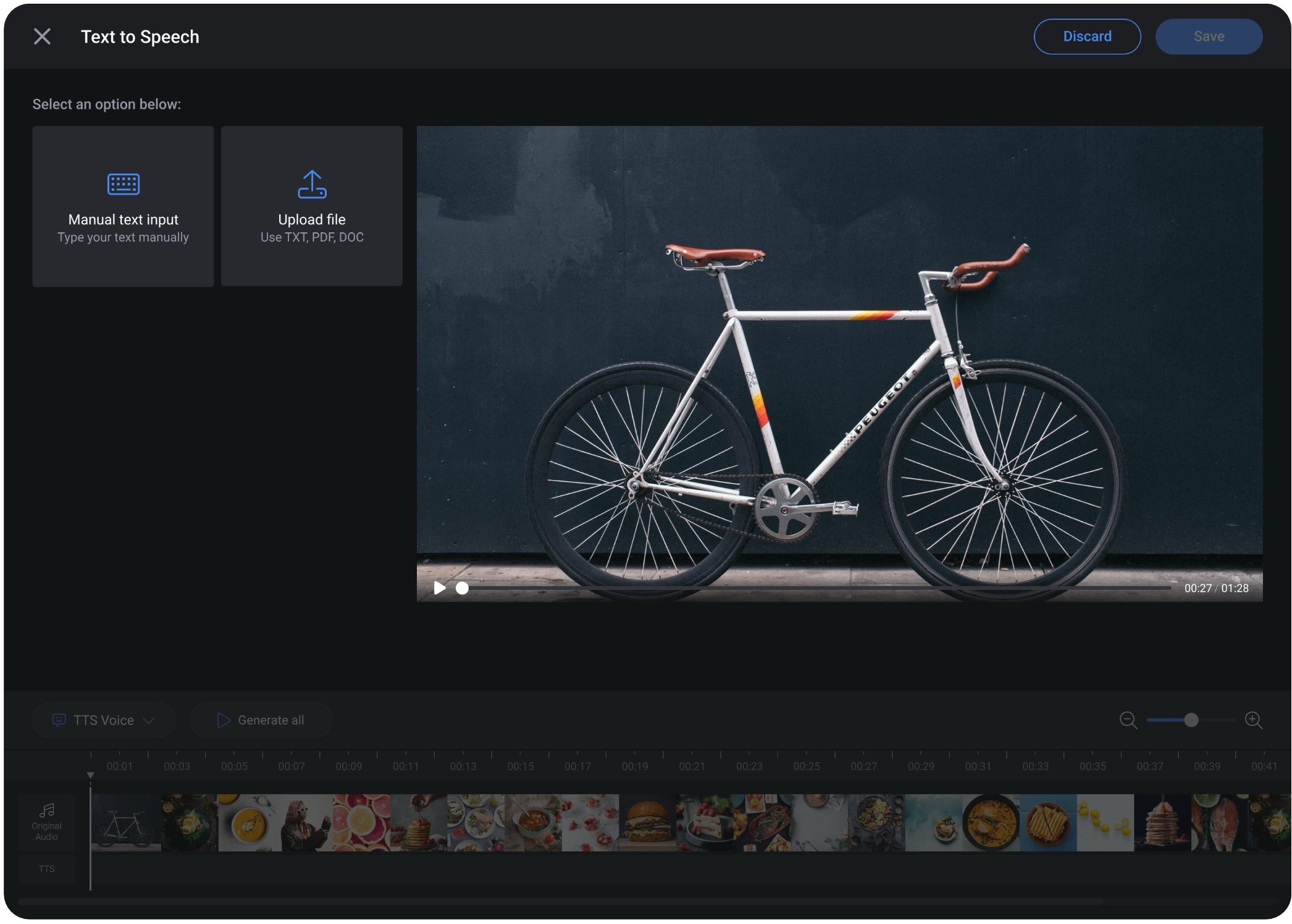
Rather than forcing one path, experts could type a script inline, paste from an existing document, or upload a file. The system handled the rest. The goal was to meet experts where they already were , not ask them to learn a new workflow from scratch.
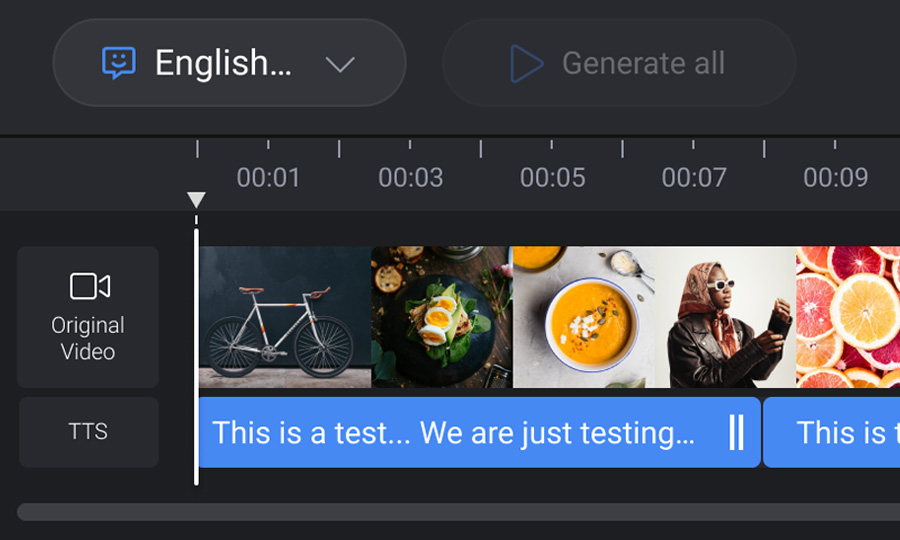
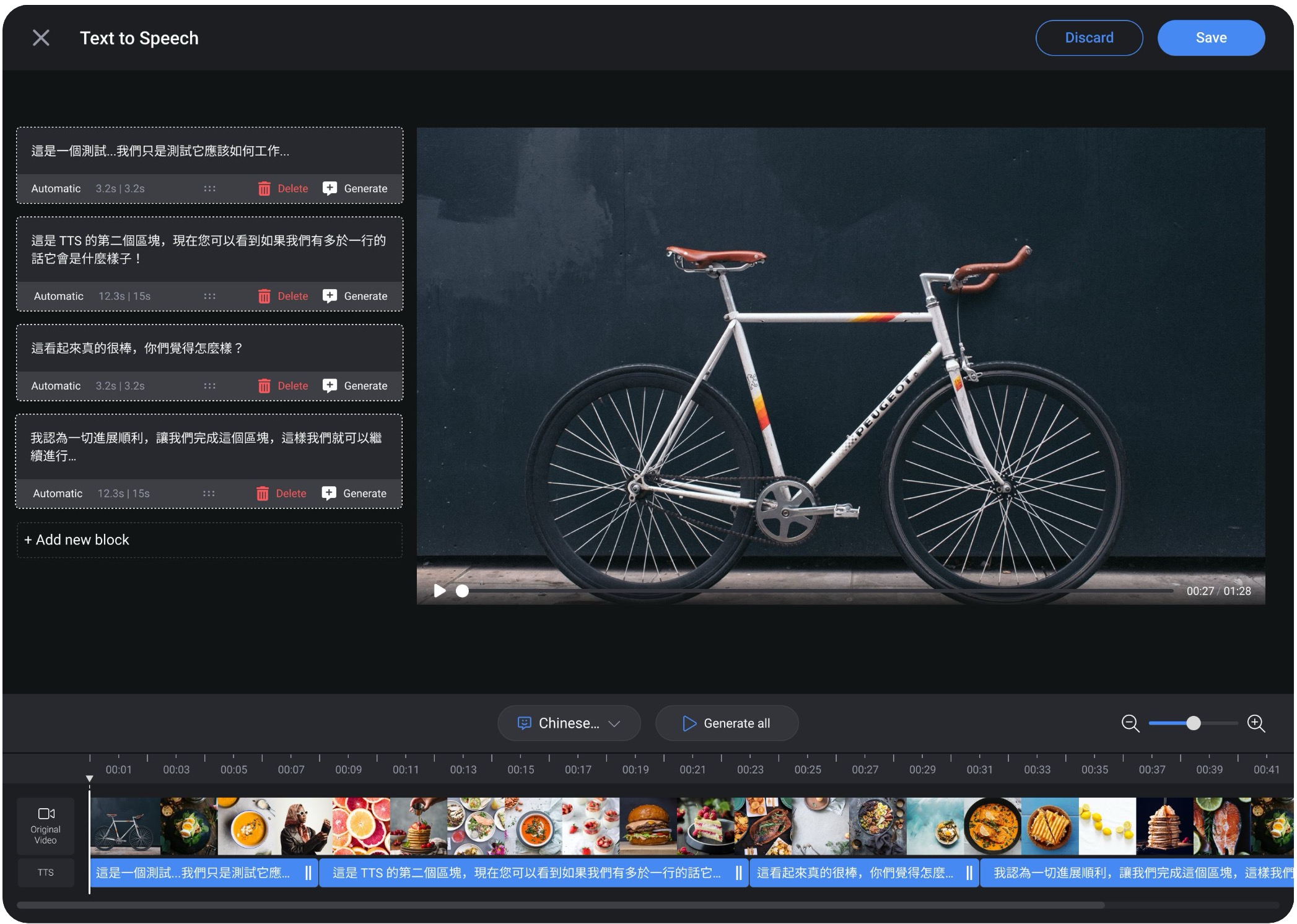
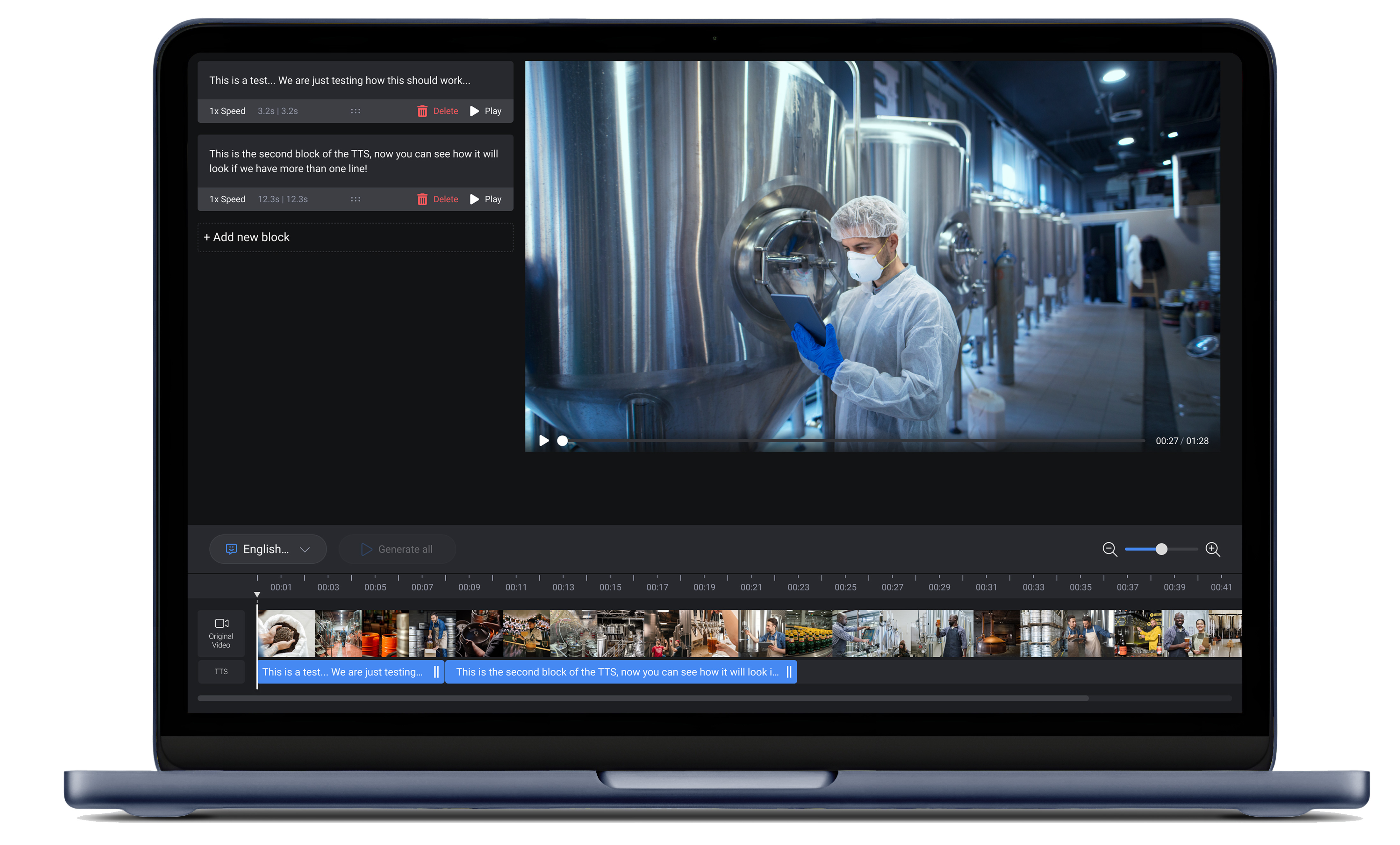
Make AI narration feel editable and trustworthy
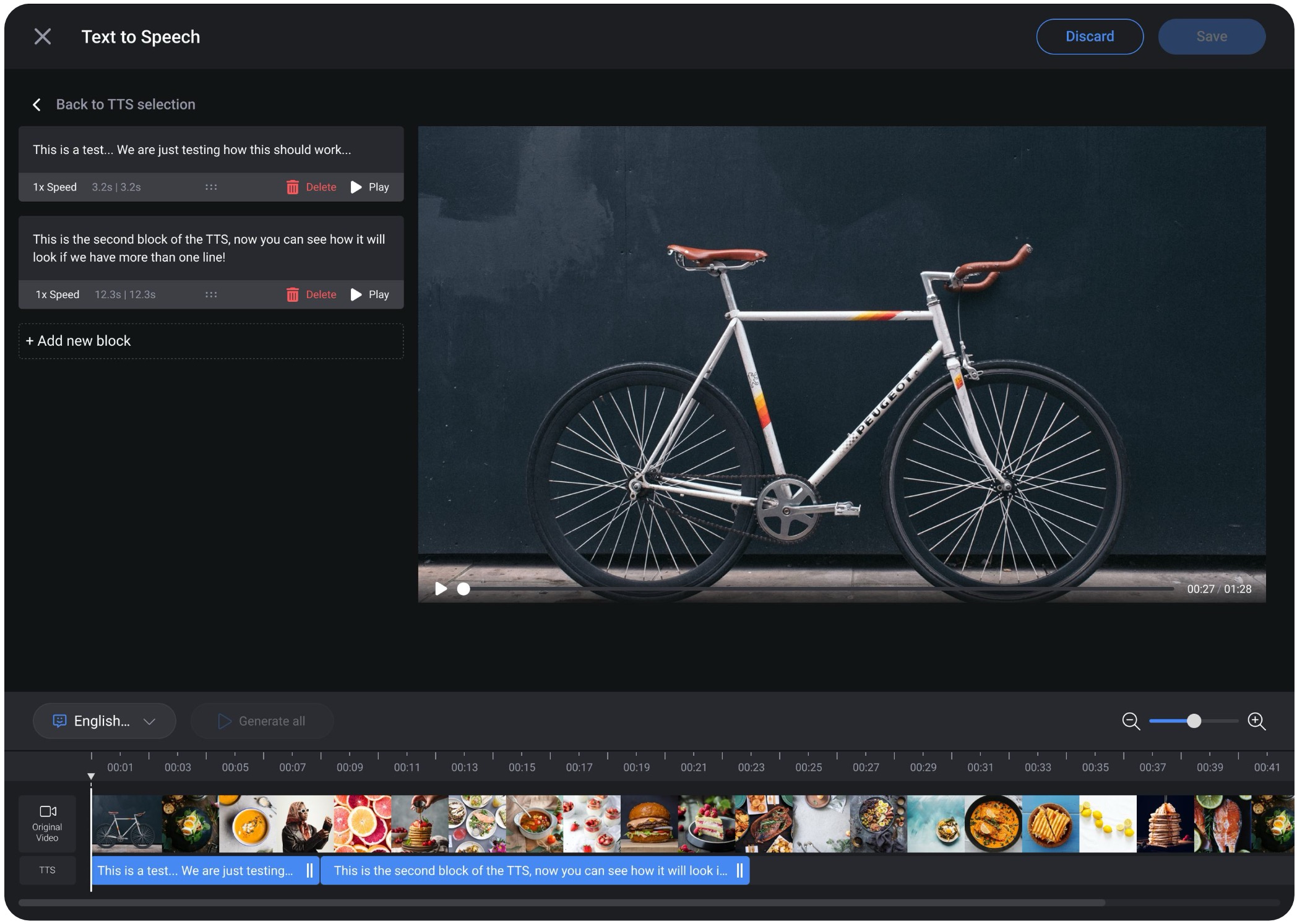
Generated audio that can't be adjusted isn't usable. I designed a timeline interface where experts could drag clips, insert pauses, and control pacing , all without video editing skills. The goal was to feel like a word processor, not a DAW.
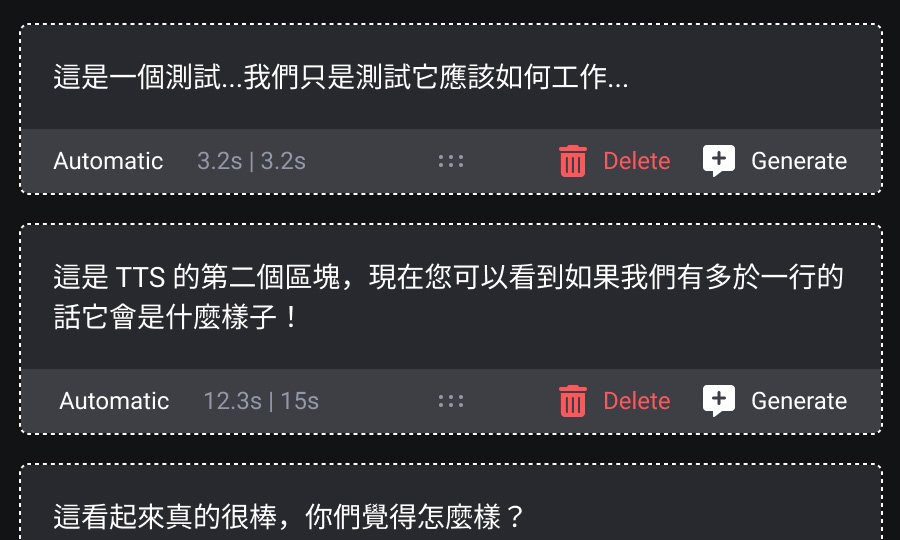
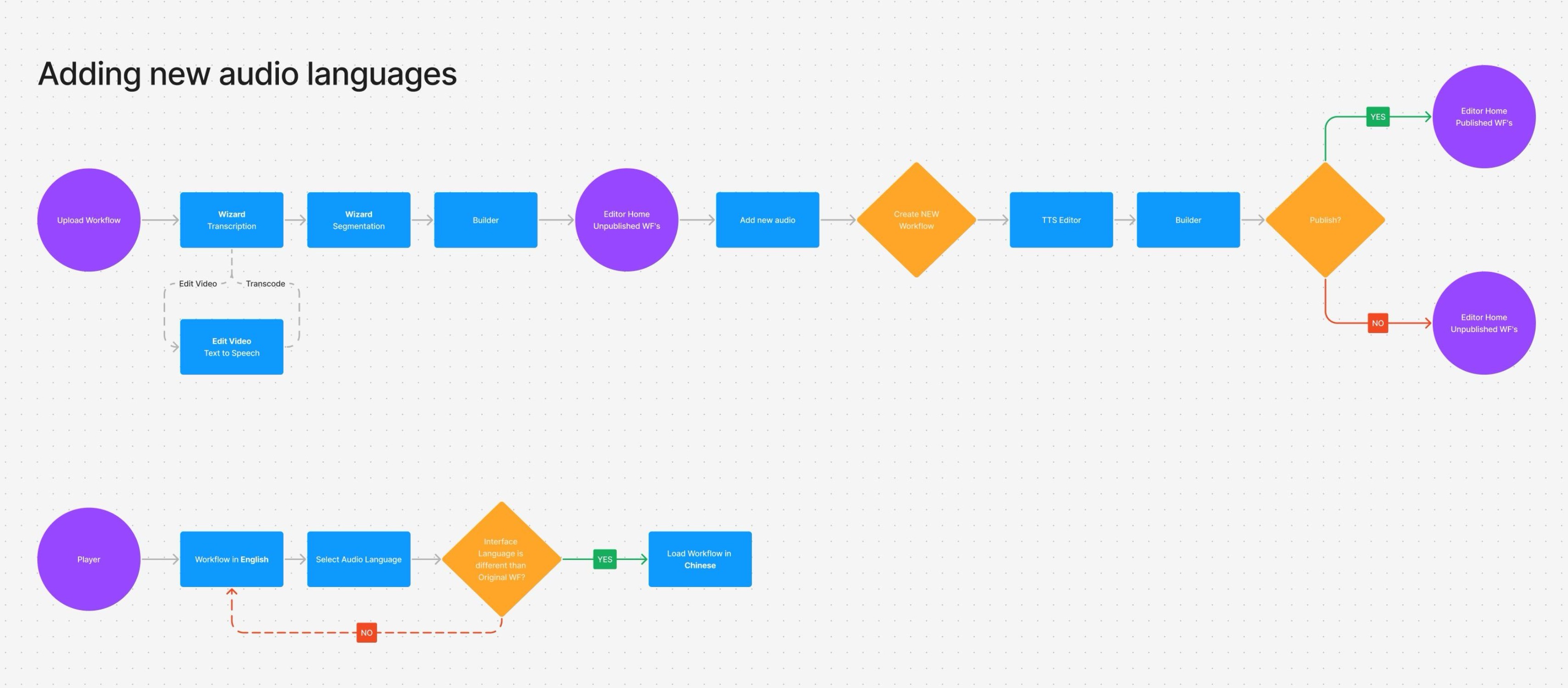
Scale operational knowledge globally
A client request revealed a larger opportunity: one-click translation that generated a fully localized version of a workflow , new script, new TTS audio in the target language, automatically synced to the original video. No re-recording. We shipped 40 languages.
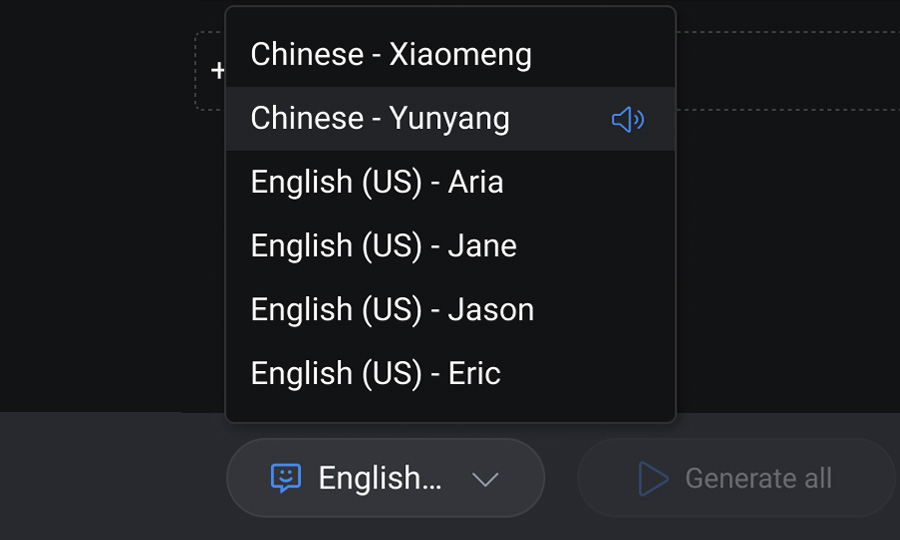
Preserve authorship and human control
Experts needed to feel that the AI voice represented them, not replaced them. A curated set of voices with real-time preview before publishing gave experts authorial control and made the final output feel deliberate. Voice choice became a moment of creative ownership.
Final Design
Two systems. One coherent product.
AI-powered TTS workflow.
Experts could generate professional voiceovers without recording their own voice, while still maintaining control over pacing, timing, and final delivery. The workflow balanced automation with lightweight editing tools that felt approachable even for non-technical users.
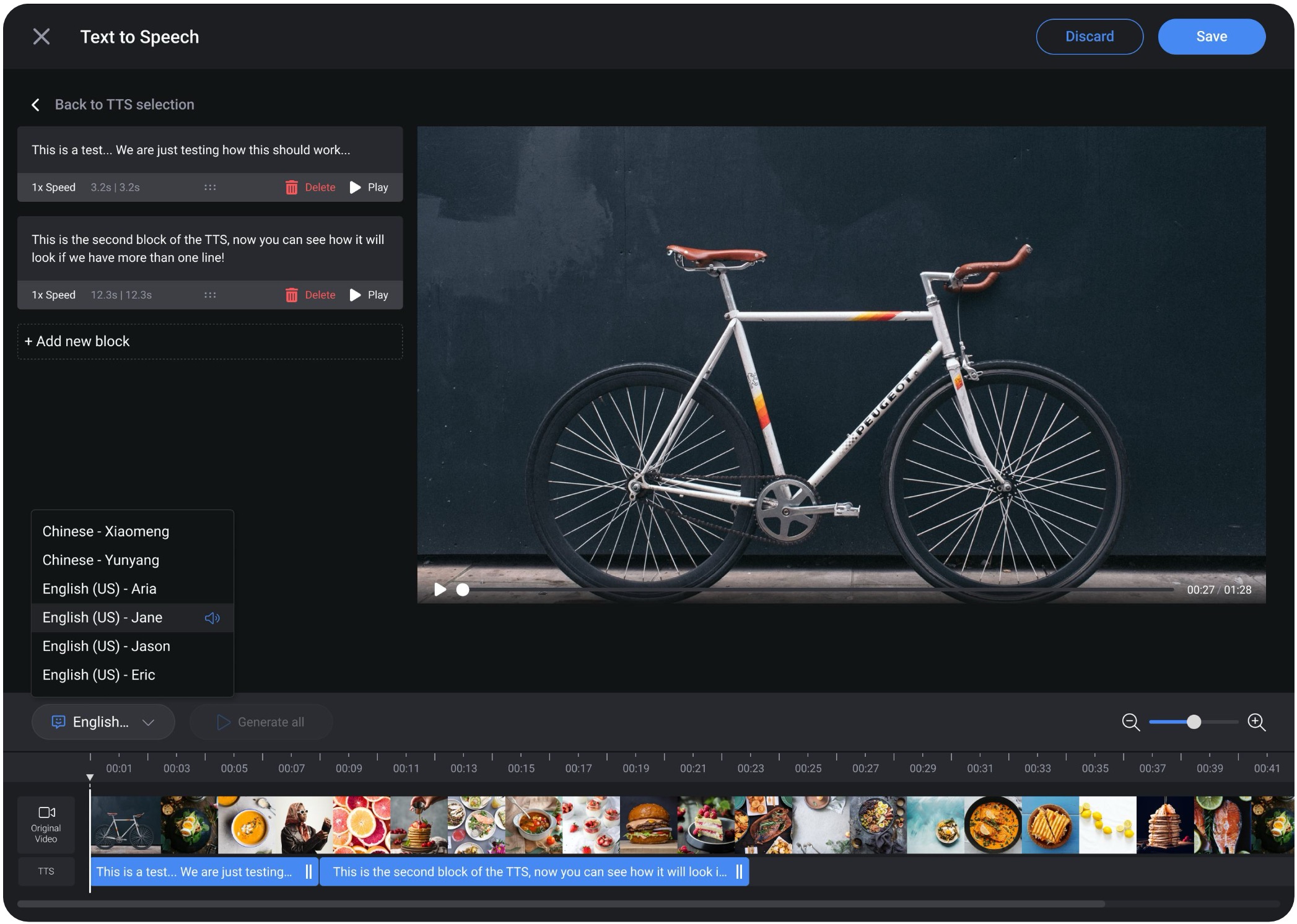
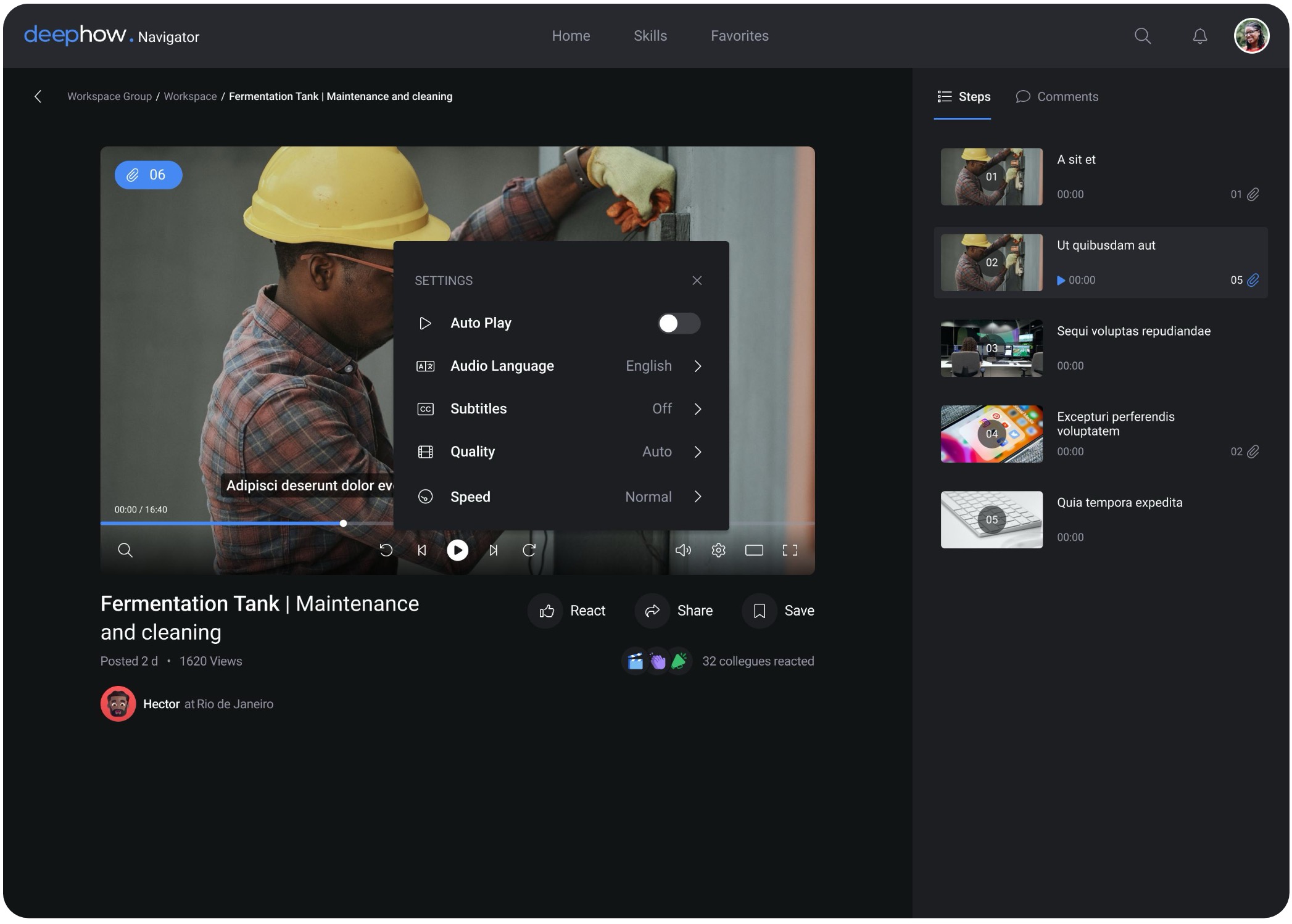
One workflow, multiple languages.
Organizations could instantly generate localized workflow versions in multiple languages without rebuilding content or re-recording audio. Translated workflows automatically appeared in each user's preferred language, making global training distribution feel seamless across factories and teams.